데이터 중심 애플리케이션 설계 (1)

최근 “데이터 중심 애플리케이션 설계”라는 책을 읽고 있다.
참 많은 내용을 담고 있는데 이책을 읽으면서 드는 생각은 왜 이책을 이제서야 읽게 되었을까라는 생각이다.
내가 경험하고 고민했던 내용들이 많이 담겨져 있어서 이책을 읽어나가면서 내용을 블로그에 정리하고자 포스팅을 시작했다.

일반적으로 데이터 중심 애플리케이션은 공통으로 필요로 하는 기능을 제공하는 표준 구성 요소(stanard building block)로 만든다.
- 데이터를 저장 (데이터베이스 : Mysql, Oracle, MongoDB, etc)
- 값비싼 수행 결과를 기억 (캐시 : Redis, Memcached, etc)
- 사용자가 키워드로 데이터를 검색 혹은 필터링 (검색 색인 : Elasticsearch, Solr, etc)
- 비동기 처리를 위해 다른 프로세스로 메시 전송 (Kafka, RabbitMQ, etc)
- 주기적으로 대량의 누적된 데이터를 분석 (MapReduce, etc)
이제는 너무 당연하게 느껴지는 구성요소이다. 대부분 엔지니어들은 잘 구성된 도구를 사용하여 위 기능들을 구현한다.
하지만 말처럼 쉬운 일은 아니다. 애플리케이션 마다 요구사항이 다르기 때문에 어떤 도구와 어떤 접근방식이 가장 적합할지 고민해야한다.
데이터 시스템에 대한 생각
데이터 저장과 처리를 위한 여러 새로운 도구들은 최근에 만들어졌다. 새로운 도구들은 다양한 사용사례에 최적화되었기 때문에, 더 이상 전통적인 분류에 딱 들어맞지 않는다. 또한 단일 도구로는 더 이상 데이터 처리와 저장을 모두 만족시킬 수 없다. 대신에 작업을 여러 테스크로 쪼개고, 각 테스크를 처리할 수 있는 여러 도구들을 사용하는 추세이다.
새로운 도구들은 다양한 사용 사례(use case)에 최적화됐기 때문에 더 이상 전통적인 분류에 딱 들어맞지 않는다.
예를 들면, 메시지 큐로 사용하는 레디스가 있으며 데이터베이스처럼 지속성(durability)를 보장하는 카프카가 있다. 즉, 분류 간 경계가 흐려지고 있다.
여러 도구들은 각기 API를 활용해 통신하고, 개발자는 클라이언트가 일관된 결과를 볼 수 있게 캐시를 삭제하거나 업데이트 하는 등의 동작을 수행한다.
이런 시스템을 설계하는 데는 여러가지를 고려하여야 한다.
- 내부적으로 문제가 있더라도 데이터를 안전하고 정확하게 유지하려면 어떻게 해야하는가?
- 시스템의 일부 성능이 저하되더라도 클라이언트에게 일관되게 좋은 성능을 제공할 수 있는가?
- 어떻게 규모를 확장할 수 있는가?
- 서비스를 위해 좋은 API란 무엇인가?
이 책에서는 대부분의 소프트웨어 시스템에서 중요하게 여기는 세 가지 관심사에 중점을 둔다.
- 신뢰성
- 하드웨어 혹은 소프트웨어 결함. 심지어 인적 오류(human error) 같은 역경에 직면하더라도 시스템은 올바르게 동작해야한다.
- 확장성
- 시스템의 데이터 양, 트래픽 양, 복잡도가 증가하면서 이를 처리할 수 있는 적절한 방법이 있어야한다.
- 유지보수성
- 시간이 지남에 따라 여러 다양한 사람들이 시스템 상에서 작업할 것이기 때문에 모든 사용자가 시스템 상에서 생산적으로 작업할 수 있게 해야 한다.
신뢰성
소프트웨어의 경우 일반적인 기대치는 다음과 같다.
- 애플리케이션은 사용자가 기대한 기능을 수행한다.
- 시스템은 사용자가 범한 실수나 예상치 못한 소프트웨어 사용법을 허용할 수 있다.
- 시스템 성능은 예상된 부하와 데이터 양에서 필수적인 사용 사례에 따라 사용할 수 있다.
- 시스템은 허가되지 않은 접근과 오남용을 방지한다.
위의 기대치가 “올바르게 동작함” 을 의미한다면, 신뢰성이란 대략 “무언가 잘못되더라도 지속적으로 올바르게 동작함” 이라고 이해할 수 있다.
잘못될 수 있는 일을 결함(fault)이라 부른다. 그리고 결함을 예측하고 대처할 수 있는 시스템을 내결함성(fault-tolerant) 또는 탄력성(resilient)을 지녔다고 한다. 또한 결함은 장애와 동일하지 않는데, 결함은 시스템의 한 구성 요소가 잘못된 것이지만 장애는 시스템 전체가 멈춰 사용자에게 필요한 서비스를 제공하지 못하는 것이기 때문이다. 결함 확률을 0으로 줄이는건 불가능하기 때문에, 결함으로 인해 장애가 발생하지 않게끔 내결함성 구조를 설계하는것이 가장 좋다.
고의적으로 결함을 유도함으로써 내결함성 시스템을 지속적으로 훈련하고 테스트해서 결함이 자연적으로 발생했을 때 올바르게 처리할 수 있도록 하는것도 좋은 방법이다.
넷플릭스의 카오스몽키(Chaos Monkey)가 이런 접근 방식의 예이다.
하드웨어 결함
- 하드디스크 평균 장애 확률 : 평균 장애 시간은 10 ~ 50년으로 보고되고 있다. 따라서 10,000개의 디스크로 구성된 저장 클러스터는 하루에 한 개의 디스크가 사망한다고 예상할 수 있다.
시스템 장애율을 줄이기 위해서는 각 하드웨어 구성 요소에 중복을 추가하는 방법이 일반적이다. RAID 를 구성하고, 서버는 이중전원 디바이스와 핫스왑이 가능한 CPU를 사용한다. 하드웨어 중복 구성을 하는 시스템은 운영상 이점이 있다. 장비를 재부팅(패치) 해야하는 경우 단일 서버 시스템은 계획된 중단시간이 필요하지만 장비 장애를 견딜 수 있는 시스템은 전체 시스템의 중단시간 없이 한 번에 한 노드씩 패치할 수 있다.
소프트웨어 오류
- 잘못된 특정 입력이 있을 때 모든 애플리케이션 서버 인스턴스가 죽는 소프트웨어 버그
- CPU 시간, 메모리, 디스크 공간, 네트워크 대역폭처럼 공유 자원을 과도하게 사용하는 일부 프로세스
- 시스템의 속도가 느려져 반응이 없거나 잘못된 응답을 반환하는 서비스
- 한 구성 요소의 작은 결함이 다른 구성 요소의 결함을 야기하고 차례차례 더 많은 결함이 발생하는 연쇄 장애
소프트웨어의 체계적 오류 문제는 신속한 해결책이 없다. 시스템의 가정과 상호작용에 대해 주의 깊게 생각하고, 테스트를 빈틈없이 하고, 프로세스를 격리하고, 죽은 프로세스의 재시작을 허용하고 프로덕션 환경에서 시스템의 동작을 측정 및 모니터링 해야한다.
인적 오류
- 오류의 가능성을 최소화하는 방향으로 시스템을 설계하라.
- 사람의 실수로 장애가 발생할 수 있는 부분을 분리하라.
- 단위 테스트부터 시스템 통합 테스트, 수동 테스트까지 모든 수준에서 철저하게 테스트하라.
- 인적 오류를 빠르게 쉽게 복구할 수 있게 하라.
- 성능 지표와 오류율 같은 상세하고 명확한 모니터링 대책을 마련하라.
- 조작 교육과 실습을 시행하라.
신뢰성은 얼마나 중요할까?
비즈니스 애플리케이션에서 버그는 생산성 저하의 원인이고, 시스템의 중단은 매출에 손실이 발생하고 명성에 타격을 준다는 면에서 많은 비용이 든다. 중요하지 않은 애플리케이션이라고 해도 사용자에 대한 책임이 있다.
프로토타입 혹은 매우 이익률이 작은 서비스의 운영 비용을 줄이기 위해 신뢰성을 희생해야 하는 경우가 있다. 하지만 이 경우에는 비용을 줄여야 하는 시점을 매우 잘 알고 있어야 한다.
확장성
시스템이 현재 안정적으로 동작한다고 해서 미래에도 안정적으로 동작한다는 보장은 없다. 성능 저하를 유발하는 흔한 이유 중 하나는 부하 증가이다.
확장성은 증가한 부하에 대처하는 시스템 능력을 설명한다.
부하 기술하기
시스템의 현재 부하를 간결하게 기술해야 한다. 그래야 부하 성장 질문(부하가 두 배로 되면 어떻게 될까?)을 논의할 수 있다.
부하는 부하 매개변수(load parameter)라 부르는 몇 개의 숫자로 나타낼 수 있다.
- 웹 서버의 초당 요청 수
- 데이터베이스의 읽기 쓰기 비율
- 대화방의 동시 활성 사용자
- 캐시 적중률
성능 기술하기
일단 시스템 부하를 기술하면 부하가 증가할 때 어떤 일이 일어나는지 조사할 수 있다. 다음 두 가지 방법으로 살펴볼 수 있다.
- 부하 매개변수를 증가시키고 시스템 자원(CPU, 메모리, 네트워크 대역폭 등)을 변경하지 않고 유지하면 시스템의 성능은 어떻게 영향을 받을까?
- 부하 매개변수를 증가시켰을 때 성능이 변하지 않고 유지되기를 원한다면 자원을 얼마나 많이 늘려야 할까?
두 질문 모두 아래와 같은 성능 수치가 필요하다.
- 처리량(throughput) : 초당 처리할 수 있는 레코드 수나 일정 크기의 데이터 집합을 처리할 때 걸리는 전체 시간
- 응답 시간(response time) : 클라이언트가 요청을 보내고 응답을 받는 사이의 시간
일반적으로 평균 값을 많이 사용할텐데 평균보다는 백분위(percentile)을 사용하는 편이 더 좋다. 응답 시간 목록을 가지고 가장 빠른 시간부터 제일 느린 시간까지 정렬하면 중간 지점이 중간값(median)이 된다. 예를들어, 중간값이 200ms면 사용자 요청의 반은 200ms미만으로 반환되고 나머지는 그보다 오래 걸린다는 뜻이다.
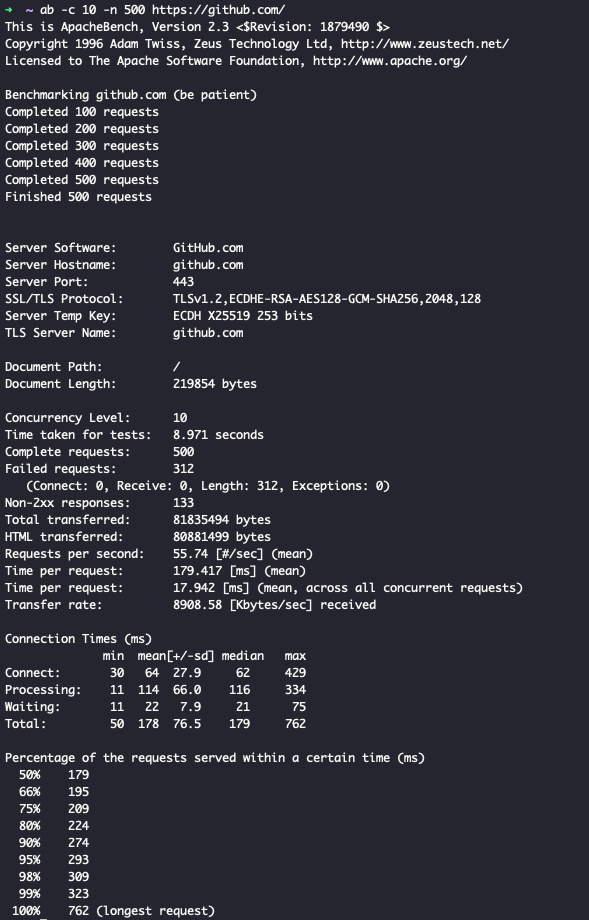
apache ab test를 해보면 응답시간을 백분위로 표시해주는데 평균 값보다 더 많은 정보를 표시해주고 있다. (-e csv-file 옵션을 넣는다면 1~100%까지 확인할 수 있다.)
부하 대응 접근 방식
증가한 부하에 대응하기 위해서는 대표적으로 2가지 방법이 있다.
- scaling up
- 고성능의 장비로 업그레이드
- scaling out
- 비슷한 성능의 장비를 추가
스케일업은 분할 구성이 어려운 시스템에 많이 쓰이는 대응 방식이며 분할 구성이 가능한 시스템은 스케일아웃으로 처리하는게 유용하다. 아무리 스케일업을 하더라도 단일 서버의 한계가 존재하기 때문에 분산 서버로 스케일아웃 가능한 시스템을 만드는것이 좋다.
유지보수성
소프트웨어 비용의 대부분은 초기 개발이 아니라 지속해서 이어가는 유지보수에 들어간다. 이런 유지보수에는 버그수정, 시스템 운영 유지, 장애 조사, 새로운 플랫폼 적용, 기술 부채 상환, 새로운 기능 추가 등이 있다.
이런 유지보수의 고통을 최소화 하도록 설계하가 위해 주의를 기울여야 할 소프트웨어 시스템 설계 원칙은 다음 세 가지다.
- 운용성(operability)
- 운영팀이 시스템을 원활하게 운영할 수 있게 쉽게 만들어라
- 단순성(simplicity)
- 시스템에서 복잡도를 최대한 제거해 새로운 엔지니어가 시스템을 이해하기 쉽게 만들어라
- 발전성(evolvability)
- 엔지니어가 이후에 시스템을 쉽게 변경할 수 있게 하라
운용성: 운영의 편리함 만들기
좋은 운영성이란 동일하게 반복되는 태스크를 쉽게 수행하게끔 만들어 운영팀이 고부가가치 활동에 노력을 집중한다는 의미이다.
단순성 : 복잡도 관리
복잡도는 크게 2가지로 나눌 수 있다.
- 필수적 복잡성(Essential complexity) : 어플리케이션이 해결해야하는 본질적 문제에 따른 복잡성
- 부수적 복잡성(Accidental complexity) : 어플리케이션 개발을 위해 사용하는 도구에 따른 복잡성
프로젝트가 커짐에 따라 시스템은 매우 복잡해지고 이해하기 어려워진다. 복잡도는 다양한 증상으로 나타난다. 상태 공간의 급증, 모듈 간 강한 커플링, 복잡한 의존성, 일관성 없는 명명과 용어, 성능 문제 해결을 목표로 한 해킹, 임시방편으로 문제를 해결한 특수 사례 등이 이런 증상이다.
복잡도를 줄이면 소프트웨어 유지보수성이 크게 향상된다. 따라서 단순성이 구축하려는 시스템의 핵심 목표여야한다.
복잡도를 제거하기 위한 최상의 도구는 추상화이다. 좋은 추상화는 깔끔하고 직관적인 외관 아래로 많은 세부 구현을 숨길 수 있다.
발전성 : 변화를 쉽게 만들기
시스템의 요구사항은 지속적으로 변화한다. 데이터 시스템 변경을 쉽게 하는 건 시스템의 간단함과 추상화와 밀접한 관련이 있다. 이해하기 쉬운 시스템은 수정하기 쉽다.
아래와 같은 방법을 사용하여 시스템의 수정을 쉽게 만들 수 있다.
- TDD(test-driven development)
- Refactoring
Comments