메모리 최적화 링크드 리스트(xor linked list)

A Memory-Efficient Doubly Linked List
책을 보던중 재밌는 개념을 봤다.
바로 “메모리 최적화 이중 연결 리스트”
기존의 이중 연결 리스트는 이전 노드의 주소와 다음 노드의 주소를 모두 기억하는 구조이다.
하지만 메모리 최적화 이중 연결 리스트는 아래와 같은 배타적 논리합의 성질을 이용하여 하나의 포인터 변수에 이전 노드와 다음 노드의 주소를 모두 기억한다.
(X⊕Y)⊕Y=X
즉 하나의 포인터 변수에 이전 노드의 주소 값과 다음 노드의 주소 값을 xor연산해서 저장하고 이전 노드 혹은 다음 노드에 대해 접근이 필요할 때마다 xor연산을 통해 주소를 다시 구하는 방식이다.
참으로 신박한 방법이 아닐 수 없다.
하지만 시간 효율성에서 차이가 있을지 없을지 궁금해서 직접 테스트를 해봤다.
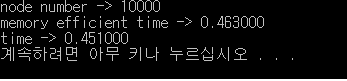
10000개 생성에 대한 테스트
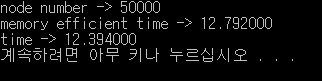
50000개 생성에 대한 테스트
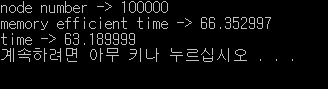
100000개 생성에 대한 테스트
연결 리스트 생성 시 모두 tail insert하여 worst case로 계산하였다.
시간 차이를 보면 1만개와 5만개의 경우 시간차이가 없다고 봐도 무방할 것 같다.
10만개의 경우는 3초 가량 차이가 나는데..
이 차이가 얼마나 증가할지 궁금해서 15만개의 노드에 대해서도 테스트를 해보기로 했다.
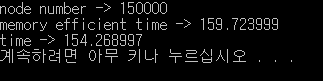
10만개 때 보다 2초 정도의 시간이 증가했지만 노드의 개수가 5만개 증가한 것이 비하면 괜찮은 수치로 보인다.
test code
typedef struct MEDoubleLinkedList
{
int data;
struct MEDoubleLinkedList *ptr;
} MEDoubleLinkedList;
void MEInsertTail(MEDoubleLinkedList **head, int data)
{
MEDoubleLinkedList* cur = head;
MEDoubleLinkedList* prev = NULL;
MEDoubleLinkedList* new = (MEDoubleLinkedList*)malloc(sizeof(MEDoubleLinkedList));
while ((MEDoubleLinkedList*)((unsigned int)prev ^ (unsigned int)cur->ptr) != NULL)
{
MEDoubleLinkedList* temp = cur;
cur = (MEDoubleLinkedList*)((unsigned int)prev ^ (unsigned int)cur->ptr);
prev = temp;
}
new->data = data;
new->ptr = (MEDoubleLinkedList*)((unsigned int)cur ^ (unsigned int)NULL);
cur->ptr = (MEDoubleLinkedList*)((unsigned int)((MEDoubleLinkedList*)(((unsigned int)cur->ptr^ (unsigned int)NULL)))^ (unsigned int)new);
}어느정도 수치가 공간 효율성이 시간 효율성을 앞서는 임계치인지는 잘 모르겠으나 재밌는 방법인 것 같다.
물론 메모리 비용이 저렴해진 현대에 와서는 큰 의미는 찾기 힘들것 같다.
최초로 소개된건 2004년도 리눅스 저널이다..!
http://www.linuxjournal.com/article/6828?page=0,0
2004년도에 소개 되었지만 2018년이 되어서야 처음 봤다…ㅠㅠ
Comments